출처 : https://bostondynamics.com/blog/large-behavior-models-atlas-find-new-footing
대규모 행동 모델과 아틀라스, 새로운 발판을 마련하다
보스턴 다이내믹스와 TRI 연구팀
유용한 휴머노이드 로봇은 수많은 역량을 필요로 할 것입니다. 이 로봇들은 단단하거나 부드러운, 무겁거나 섬세한, 고정되거나 관절이 있는, 크거나 작은 것과 같은 다양한 물체를 조작하는 능력뿐만 아니라, 스스로 자세를 바꾸고, 주변 환경을 재구성하며, 장애물을 피하고, 돌발 상황에 대응하면서 균형을 유지하기 위해 몸 전체를 조정하는 능력이 필요합니다. 우리는 AI 범용 로봇을 구축하는 것이 이러한 역량을 창출하고 휴머노이드를 통해 대규모 자동화를 달성하는 가장 실현 가능한 길이라고 믿습니다.
저희는 아틀라스를 위한 대규모 행동 모델(LBMs) 개발에 대한 진전 일부를 공유하게 되어 기쁩니다. 이 연구는 토요타 연구소(TRI)와 보스턴 다이내믹스의 AI 연구팀 간의 협력의 일환입니다. 우리는 아틀라스가 장기적인 조작 과제를 수행할 수 있도록 하는 언어 조건화된 종단 간(end-to-end) 정책을 구축해 왔습니다.
이러한 정책들은 걸음을 내딛고, 발을 정밀하게 배치하며, 웅크리고, 무게 중심을 이동시키고, 자가 충돌을 피하는 등 휴머노이드 폼팩터의 능력을 최대한 활용할 수 있습니다. 우리는 이 모든 기능이 현실적인 이동 조작 과제를 해결하는 데 매우 중요하다는 것을 발견했습니다.
정책을 구축하는 과정은 네 가지 기본 단계를 포함합니다:
실제 로봇 하드웨어와 시뮬레이션 모두에서 원격 조종을 사용하여 체화된 행동 데이터를 수집합니다. 머신러닝 파이프라인에 쉽게 통합할 수 있도록 데이터를 처리하고, 주석을 달고, 큐레이션합니다. 모든 과제에 걸친 모든 데이터를 사용하여 신경망 정책을 훈련합니다. 과제 테스트 스위트를 사용하여 정책을 평가합니다.
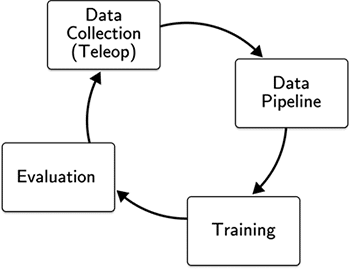
4단계의 결과는 어떤 추가 데이터를 수집해야 할지, 어떤 네트워크 아키텍처나 추론 전략이 성능 향상을 가져올지에 대한 의사 결정을 안내합니다.

당사의 정책은 이미지, 고유 수용 감각, 언어 프롬프트로 구성된 입력을 30Hz로 전체 아틀라스 로봇을 제어하는 동작으로 매핑합니다. 우리는 확산 트랜스포머(diffusion transformer)와 플로우 매칭 손실(flow matching loss)을 활용하여 모델을 훈련합니다.
이 프로세스를 구현하는 데 있어, 우리는 세 가지 핵심 원칙을 따랐습니다.
최대 작업 범위 확보: 휴머노이드는 원칙적으로 엄청나게 광범위한 조작 작업을 처리할 수 있지만, 정지된 조작 작업을 넘어선 데이터를 수집하면서 고품질의 반응성 움직임을 보존하는 것은 어렵습니다. 우리는 아틀라스의 모델 예측 제어기(MPC)와 맞춤형 VR 기반 인터페이스를 결합한 최첨단 원격 조작 시스템을 구축하여 손가락 수준의 정교함부터 전신 도달 및 이동에 이르는 모든 작업을 처리할 수 있도록 했습니다.
범용 정책 훈련: 다양한 작업 데이터의 대규모 말뭉치(corpus)로 훈련된 정책이 하나의 작업 또는 소수의 작업을 해결하기 위해 훈련된 특화된 정책보다 더 잘 일반화하고 복구할 수 있다는 증거가 꾸준히 축적되고 있습니다. 우리는 아틀라스, 상체 전용 아틀라스 조작 테스트 스탠드(MTS), TRI 라멘(Ramen) 데이터의 사전 훈련 데이터를 통합하여 다양한 신체에서 다양한 작업을 수행하는 데 다중 작업 언어 조건부 정책을 사용합니다. 범용 정책을 구축하는 것은 또한 배포를 단순화하고, 작업 및 신체 전반에 걸쳐 정책 개선 사항을 공유하며, 이머전트 행동(emergent behaviors)을 잠금 해제하는 데 더 가까이 다가갈 수 있게 합니다.
신속한 반복 및 엄격한 과학을 지원하는 인프라 구축: 설계 선택 사항을 신속하게 반복할 수 있는 능력은 중요하지만, 실제로 한 정책이 다른 정책보다 나은지 혹은 못한지를 확신을 가지고 측정하는 것이 꾸준한 진전을 이루는 핵심 요소입니다. 시뮬레이션, 하드웨어 테스트 및 프로덕션 규모를 위해 구축된 ML 인프라의 조합을 활용하여, 우리는 온-로봇(on-robot) 성능을 지속적으로 개선하면서 데이터 및 정책 설계 공간을 효율적으로 탐색할 수 있었습니다.
Long-Horizon, End-to-End Manipulation
“스팟 워크숍” 작업은 조정된 이동(걷기, 넓은 자세 설정, 웅크리기)과 부품 집기, 다시 잡기(regrasping), 관절 움직이기(articulating), 놓기, 밀어 넣기를 포함한 능숙한 조작을 시연합니다. 이 작업은 세 가지 하위 작업으로 구성됩니다:
- 카트에서 스팟 다리를 잡고 접은 다음 선반 위에 놓기.
- 카트에서 페이스 플레이트를 잡은 다음, 아래쪽 선반에 있는 통을 꺼내 페이스 플레이트를 그 통 안에 넣기.
- 카트가 완전히 비워지면, 뒤에 있는 파란색 통으로 몸을 돌려 나머지 모든 스팟 부품을 비우고, 그것들을 한 움큼씩 파란색 틸트 트럭에 넣기.
이 편집되지 않은 엔드 투 엔드 비디오에서, 우리는 세 가지 하위 작업 각각이 정책에 높은 수준의 언어 프롬프트를 전달함으로써 작동되는, 전체 작업 순서를 수행하는 단일 언어 조건부 정책을 보여줍니다.
주요 특징은 부품이 바닥에 떨어지거나 통 뚜껑이 닫히는 등 상황이 잘못되었을 때 우리 정책들이 지능적으로 반응하는 것이었습니다. 정책의 초기 버전에는 이러한 기능이 없었습니다. 로봇이 그러한 방해로부터 복구하는 예시들을 시연하고 네트워크를 재훈련함으로써, 우리는 알고리즘이나 엔지니어링 변경 없이 새로운 반응 정책들을 신속하게 배포할 수 있었습니다. 이는 정책들이 로봇의 센서로부터 세상의 상태를 효과적으로 추정하고, 오직 훈련에서 관찰된 경험을 통해 그에 따라 반응할 수 있기 때문입니다. 그 결과, 새로운 조작 행동을 프로그래밍하는 데 더 이상 고급 학위와 수년간의 경험이 필요하지 않게 되었으며, 이는 아틀라스의 행동 개발을 확장할 수 있는 매력적인 기회를 창출합니다.
Additional Manipulation Capabilities
우리는 벤치마킹 및 조작의 한계를 확장하기 위해 사용한 수십 가지 작업을 연구했습니다. 단일 언어 조건부 정책을 아틀라스 MTS에서 사용하여, 우리는 간단한 집어서 놓기(pick-and-place)부터 로프 묶기, 바 스툴 뒤집기, 식탁보 펼치고 펴기, 22파운드 자동차 타이어 조작과 같은 더 복잡한 작업에 이르기까지 다양한 작업을 수행할 수 있습니다. 로프, 천, 타이어 조작은 그 변형 가능한 기하학과 복잡한 조작 순서 때문에 전통적인 로봇 프로그래밍 기술로는 수행하기 매우 어려웠을 작업의 예시입니다. 하지만 LBM을 사용하면, 단단한 블록을 쌓는 것이든 티셔츠를 접는 것이든 훈련 과정은 동일합니다. 시연할 수 있다면, 로봇은 그것을 학습할 수 있습니다.
Adapting Performance of Policies After Learning
우리 정책의 한 가지 주목할 만한 특징은 훈련 시간 변경 없이 추론 시간(inference time)에 실행 속도를 높일 수 있다는 것입니다. 구체적으로, 우리 정책들은 미래 행동들의 궤적과 그 행동들이 취해져야 할 시간을 함께 예측하기 때문에, 우리는 이 타이밍을 조정하여 실행 속도를 제어할 수 있습니다. 아래 비디오에서 우리는 정책이 1배속(즉, 데이터 수집 중에 이 작업이 수행된 속도)으로 롤아웃될 때와 2배속 및 3배속으로 롤아웃될 때를 비교합니다. 일반적으로, 우리는 MTS와 전체 아틀라스 플랫폼 모두에서 정책 성능에 크게 영향을 미치지 않으면서 정책 속도를 1.5배~2배까지 높일 수 있다는 것을 발견했습니다. 작업 역학(task dynamics)이 때때로 이러한 종류의 추론 시간 속도 향상을 방해할 수 있지만, 이는 일부 경우에 우리가 인간 원격 조작의 속도 한계를 초과할 수 있음을 시사합니다.
접근 방식
플랫폼
아틀라스는 광범위한 움직임과 높은 수준의 정교함을 제공하는 50개의 자유도(DoF)를 포함합니다. 아틀라스 MTS는 순수 조작 작업을 탐색하기 위해 29개의 자유도를 갖추고 있습니다. 각 그리퍼는 7개의 자유도를 가지며, 이는 파워 그립, 핀치 그립 등 광범위한 파지 전략을 사용할 수 있게 합니다. 우리는 정책을 위한 시각 입력과 원격 조작을 위한 상황 인식을 모두 제공하기 위해 머리에 장착된 한 쌍의 HDR 스테레오 카메라에 의존합니다.
원격 조작: 모델 훈련을 위한 고품질 데이터 수집
로봇을 유연하고, 역동적이며, 능숙한 방식으로 제어하는 것은 매우 중요하며, 우리는 이러한 요구를 해결하기 위해 원격 조작 시스템에 막대한 투자를 했습니다. 이 시스템은 보스턴 다이내믹스(Boston Dynamics)의 MPC(모델 예측 제어) 시스템을 기반으로 구축되었으며, 이는 이전에 파쿠르, 댄스, 그리고 실용적 및 비실용적 조작에 이르는 다양한 사용 사례에 배포되었습니다. 이 제어 시스템은 균형을 유지하고 자가 충돌을 피하면서 정밀한 조작을 수행할 수 있게 하여, 우리가 아틀라스 하드웨어로 할 수 있는 것의 한계를 뛰어넘을 수 있게 합니다.
원격 조작 설정은 운영자가 로봇의 작업 공간에 완전히 몰입하고 정책과 동일한 정보에 접근할 수 있도록 VR 헤드셋을 활용합니다. 공간 인식은 아틀라스의 머리 장착 카메라를 사용하여 사용자 시점으로 다시 투영(reprojected)된 스테레오스코픽(입체) 뷰를 통해 강화됩니다. 맞춤형 VR 소프트웨어는 원격 조작자에게 로봇을 명령할 수 있는 풍부한 인터페이스를 제공하며, 증강 현실, 컨트롤러 햅틱, 헤드업 디스플레이 요소를 통해 로봇 상태, 제어 목표, 센서 판독값, 촉각 피드백, 시스템 상태의 실시간 피드를 제공합니다. 이를 통해 원격 조작자는 자신의 몸과 감각을 로봇의 그것과 동기화하여 로봇 하드웨어와 기능을 최대한 활용할 수 있습니다.
VR 원격 조작 애플리케이션의 초기 버전은 헤드셋, 베이스 스테이션, 컨트롤러, 그리고 가슴용 트래커 하나를 사용하여 아틀라스가 정지한 상태에서 제어했습니다. 이 시스템은 사용자와 로봇 간의 일대일 매핑(one-to-one mapping)을 사용하여(즉, 손을 1cm 움직이면 로봇도 1cm 움직임) 특히 양손 작업에서 직관적인 제어 경험을 제공했습니다. 이 버전으로도 운영자는 웅크려서 바닥에 있는 물체에 도달하거나, 키를 높여 높은 선반에 도달하는 등 광범위한 작업을 수행할 수 있었습니다. 하지만 이 시스템의 한계는 운영자가 발의 위치를 동적으로 재배치하고 걸음을 내딛는 것을 허용하지 않아 수행할 수 있는 작업이 상당히 제한되었다는 것입니다.
모바일 조작을 지원하기 위해, 우리는 발에 대한 일대일 트래킹을 위해 두 개의 추가 트래커를 통합하고, 아틀라스의 자세 모드(stance mode), 지지 다각형(support polygon), 발걸음 의도(stepping intent)가 운영자의 것과 일치하도록 원격 조작 제어를 확장했습니다. 이동을 지원하는 것 외에도, 이 설정은 아틀라스의 작업 공간을 최대한 활용할 수 있게 했습니다. 예를 들어, 바닥에 있는 파란색 운반 상자(tote)를 열고 내부 물건을 집을 때, 사람은 상자와 충돌하지 않고 상자 안의 물체에 도달하기 위해 로봇을 넓은 자세와 무릎을 굽힌 상태로 구성할 수 있어야 합니다.
우리 신경망 정책은 원격 조작 시스템과 동일한 제어 인터페이스를 로봇에 사용하며, 이는 단순히 행동 표현(action representation)을 보강함으로써 이전에 개발했던 모델 아키텍처(이동이 포함되지 않은 정책용)를 쉽게 재사용할 수 있도록 했습니다.
정책
토요타 리서치 인스티튜트(Toyota Research Institute)의 대규모 행동 모델(Large Behavior Models)을 기반으로 구축되었으며, 이는 확산 정책(Diffusion Policy) 유사 아키텍처를 확장합니다. 우리 정책은 4억 5천만 개의 매개변수(parameter)를 가진 확산 트랜스포머(Diffusion Transformer) 기반 아키텍처와 플로우 매칭 목표(flow-matching objective)를 함께 사용합니다. 이 정책은 고유 수용 감각, 이미지에 의해 조건화되며, 로봇에게 목표를 명시하는 언어 프롬프트도 받아들입니다. 이미지 데이터는 30Hz로 입력되며, 우리 네트워크는 48 길이의 행동 덩어리(action-chunk)(1.6초에 해당)를 예측하기 위해 과거 관측치를 사용합니다. 이 때 일반적으로 24개의 행동(1배속 실행 시 0.8초)이 정책 추론이 실행될 때마다 실행됩니다.
아틀라스에 대한 정책의 관측 공간(observation space)은 로봇의 머리 장착 카메라에서 얻은 이미지와 고유 수용 감각으로 구성됩니다. 행동 공간(action space)에는 왼쪽 및 오른쪽 그리퍼의 관절 위치, 목 요(yaw), 몸통 자세, 왼쪽 및 오른쪽 손 자세, 그리고 왼쪽 및 오른쪽 발 자세가 포함됩니다.
아틀라스 MTS는 기계적 관점과 소프트웨어 관점 모두에서 아틀라스의 상체와 동일합니다. 관측 및 행동 공간은 몸통 및 하체 구성 요소가 생략되었다는 점만 제외하고 아틀라스와 동일합니다. 아틀라스와 아틀라스 MTS 전반에 걸친 이러한 공유 하드웨어 및 소프트웨어는 두 플랫폼에서 모두 기능할 수 있는 다중 신체 정책(multi-embodiment policies) 훈련에 도움을 주어, 두 신체에서 데이터를 모을 수 있게 합니다.
이러한 정책들은 팀이 지속적으로 수집하고 반복한 데이터를 기반으로 훈련되었으며, 고품질 시연이 성공적인 정책을 얻는 데 결정적인 부분이었습니다. 우리는 수집된 데이터에 대한 검토, 필터링, 피드백 제공을 가능하게 한 품질 보증 도구(quality assurance tooling)에 크게 의존했습니다.
시뮬레이션
시뮬레이션은 원격 조작 시스템을 신속하게 반복하고, 손상 없이 앞으로 나아갈 수 있도록 단위 및 통합 테스트를 작성하며, 하드웨어에서 반복적으로 수행하기에는 더 느리고, 더 비싸고, 어려운 정보를 제공하는 훈련 및 평가를 수행할 수 있게 하는 중요한 도구입니다. 우리의 시뮬레이션 스택은 하드웨어와 온-로봇 소프트웨어 스택을 충실하게 표현하므로, 우리는 데이터 파이프라인, 시각화 도구, 훈련 코드, VR 소프트웨어 및 인터페이스를 시뮬레이션과 하드웨어 플랫폼 모두에서 공유할 수 있습니다.
우리는 정책 및 아키텍처 선택을 벤치마킹하기 위해 시뮬레이션을 사용하는 것 외에도, 하드웨어에 배포하는 다중 작업 및 다중 신체 정책을 위한 중요한 공동 훈련 데이터 소스로 시뮬레이션을 통합합니다.
결론 및 다음 단계
우리는 이동(locomotion)과 능숙한 전신 조작(dexterous whole-body manipulation)을 모두 포함하는 장기적 작업(long-horizon tasks)을 수행하기 위해 아틀라스를 제어할 수 있는 다중 작업 언어 조건부 정책을 훈련할 수 있음을 보여주었습니다. 우리의 데이터 기반 접근 방식은 일반적이며, 원격 조작을 통해 시연할 수 있는 거의 모든 다운스트림 작업에 사용될 수 있습니다.
지금까지의 결과에 고무되기는 하지만, 여전히 해야 할 일이 많습니다. 확립된 작업 및 성능의 기준선을 바탕으로, 우리는 새로운 알고리즘 아이디어를 탐색하는 동시에 처리량, 품질, 작업 다양성 및 난이도를 높이기 위해 데이터 플라이휠을 확장하는 데 집중할 것입니다.
우리는 성능 관련 로봇 공학 주제(예: 촉각 피드백을 통한 그리퍼 힘 제어, 빠른 동적 조작), 다양한 데이터 소스 통합(교차 신체, 자기 중심적 인간 데이터 등), VLA의 강화 학습 개선, 그리고 VLM/VLA 아키텍처 배포를 포함하여 더 복잡한 장기적 작업 및 개방형 추론을 가능하게 하는 여러 연구 방향을 추구하고 있습니다.
이러한 주제에 흥미가 있고 세계적 수준의 연구원, 엔지니어 및 로봇과 함께 일하고 싶다면, 보스턴 다이내믹스와 토요타 리서치 인스티튜트로 연락해 주십시오.
Authorship
This article was written with the support of teams from Boston Dynamics and TRI. Contributors are listed below in alphabetical order; organization affiliation is indicated in superscript (B for Boston Dynamics and T for TRI), project leads are indicated with one asterisks (*), and organization leaders with two ().
LBM Team: Jun AhnB, Alex AlspachT, Kevin BergaminB, Benjamin BurchfielT, Eric CousineauT*, Aidan CurtisB, Siyuan FengT, Kerri Fetzer-BorelliT, Dion GonanoB, Rachel HanB, Scott KuindersmaB – BD Lead, Lucas ManuelliB*, Pat MarionB*, Daniel MartinB, Aykut OnolT, Russ TedrakeT – TRI Lead, Russell WongB, Mengchao ZhangT, Mark ZolotasT
Data Operations: Keelan BoyleB, Matthew FerreiraT, Cole GlynnB, Brendan HathawayT, Allison HenryT, Phoebe HorganT, Connor KeaneB, Ben StrongB, ThienTran LeB, Dominick LeiteB, David TagoT, Matthew TranT
Blog Authors: Eric Cousineau, Scott Kuindersma, Lucas Manuelli, Pat Marion
'로봇' 카테고리의 다른 글
| Figure AI 휴머노이드 로봇 회사 (0) | 2025.10.18 |
|---|---|
| 4족 보행 로봇, Unitree 구매 후 개발하기 (0) | 2025.09.28 |
| 로봇 물리 시뮬레이터 MuJoCo (0) | 2025.09.28 |
| NVIDA Isaac Omniverse, Isaac Sim, Issac Lab, GR00T 등 비교 정리 (0) | 2025.09.28 |
| Gemini Robotics 1.5 brings AI agents into the physical world(한국어) (0) | 2025.09.28 |